When I set out to work on this tool for The Raiser's Edge, first and foremost I thought it needs to be user-friendly; where someone without any technical skills (e.g. writing SQL), could run the application and gain valuable insights into their data. As a result I think I have a tool that is a must for every organization to own and use. I usually create stuff and give them away for FREE, but I think this product is so revolutionary in where it will be heading in the future that I am trying to figure out a pricing structure for it. But at the end of the day it will be priced so that everyone can afford it, likely without any high, upfront costs as is typical for much of the software today, but perhaps a subscription model.
What makes the application compelling and worth spending money on? Well, to my knowledge, there is no product out in the marketplace that has taken the best practices for profiling data and made it available in a product for The Raiser's Edge. If you were to profile your data you would have to have someone with the technical expertise to use tools such as SSIS and Informatica Data Quality to create profiles that allow you to measure, evaluate, and discover data problems. But these have problems as they don't allow for the integration with The Raiser's Edge or they are crazy expensive. Would you rather spend tens of thousands of dollars (if not more) or likely just hundreds (pricing TBD) each year?
In addition, the application allows you to look at your data from a whole new perspective. It is designed to allow you to view this data in such a way that you can discover where you have data issues. For example, you may have a segment of your constituents (or profile view as it is called in the application) where the Title 1 is equal to "Mr.". In the profile view you will see all of the different genders for this segment of constituents, including potentially any genders that are "Female" or "Unknown". Well, this is a problem that you likely want to fix. The tool can't fix this issue, at least not yet :), but it has clearly pointed out and made visible to you where a data issue exists.
Before we get into it, lets hit some of the highlights (or goals), of what I wanted to accomplish and what the product offers:
- Best practices data profiling results for segments of Raiser's Edge records. This includes reporting on the number of unique values and % unique, number of null values, % null, number of zero length strings and % of total, maximum and minimum values and string lengths,
- Data mining capabilities to allow someone to easily mine the set of unique values (and their frequency) for a column in a segment. For example, if I were profiling those constituents that are Board Members, perhaps I want to see the unique values for state and the number of constituents with those states within my board member segmentation.
- Drill-down capabilities to see the details for records that fit a specific segment. Using my board member example above, I could then "drill-down" on those board members that live in South Carolina and see all of their details (e.g. Name, Address, constituent flags, etc.)
- Integration with The Raiser's Edge. The application allows you to open The Raiser's Edge records (Constituents, Gifts, Campaigns, Actions, etc) directly from the application.
- No writing SQL, easy to use for non-techies!
- Dynamic generation of segments to profile. For example, the application automagically creates profile views (my name for segments of records) for constituents for each of the constituent codes. Thus pre-canned profiles are already available for all of your constituent codes, as well as many other code tables and records.
- Take the idea of data profiling and let it be another query engine for The Raiser's Edge, giving users another tool to gain insight into their data (beyond statistics and profiling).
- Ability to grow and extend the application from the first release!!!
Lets take a look at some of the screen shots for the application (currently in beta form and available for trial downloads).

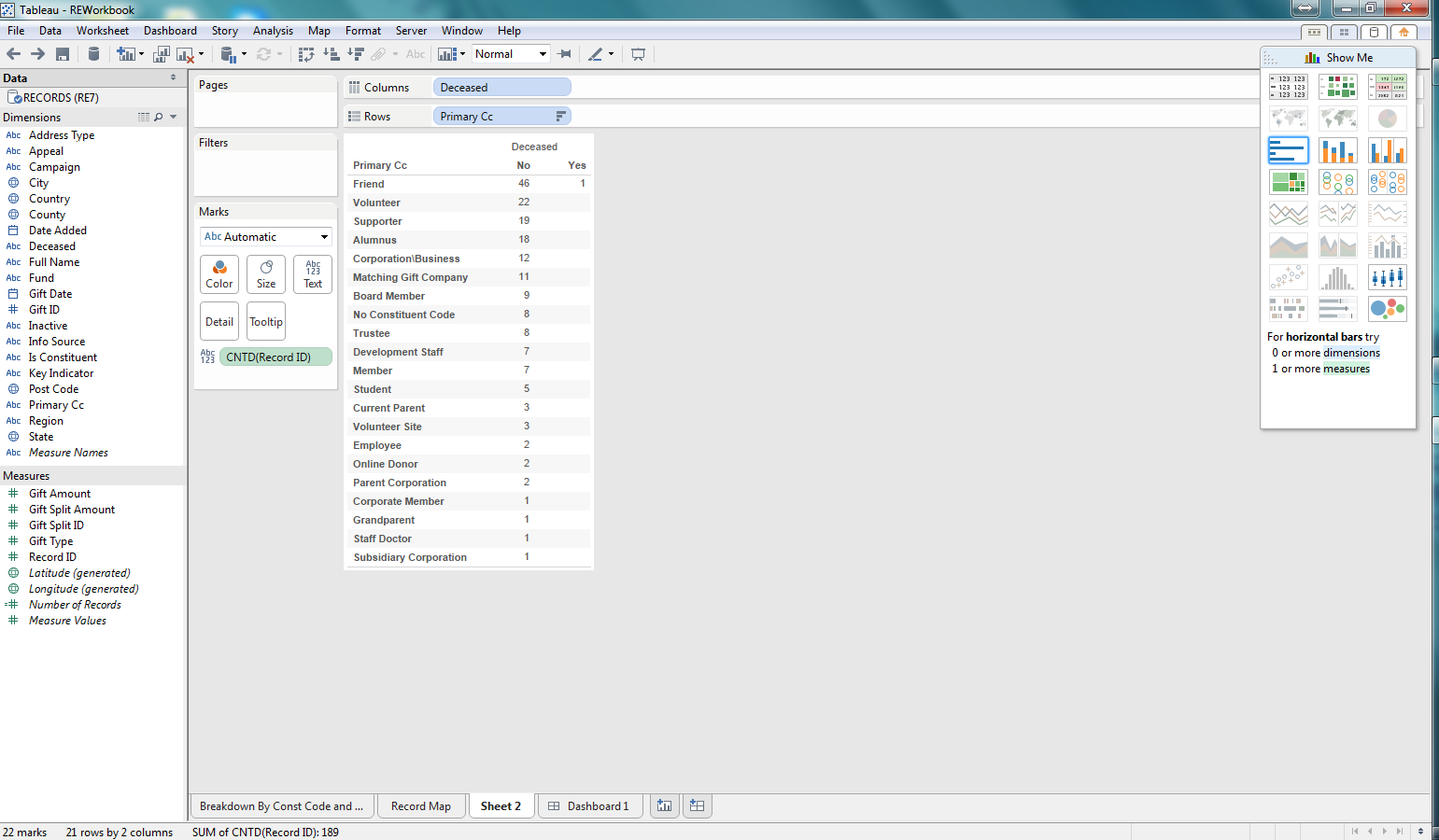
You can run the profile via a button on the toolbar, right-click context menu with the mouse, or just double-clicking the profile view. Once you "run" the profile view you will then have the form loaded with the details (as seen below). The Profile View form shows the core data profiling statistics for each column in the main table (top left). However, you have powerful capabilities, for each column to "mine the values" to see what are the different values for a column and how frequently they occur (top right table). And finally you can then drill-down, from the list of values and their frequency, to view the details of specific records within that profile view for a specific value of a column (bottom-table).

Right-click menus are used heavily on the Profile View form seen above. There are numerous options when right-clicking with your mouse that are not readily available on the toolbars, with buttons, for each of the tables. For example, as seen below, right-clicking on the Constituent Address Country column for the profile view below, I can mine the values for that column in many different ways and see the results in the table at the top-right of the form. I can even refresh my profile or export the profile view results - pretty cool.

I can also right-click on the values list table and drill-down to see the records which have a specific value for a column in my profile view. As seen in the screen-shot below, I can view the records that have a date from, in my constituent code, which is NULL. These records would then show up in the bottom table of the Profile View form.

Once you have drilled down on records you can even right-click on a specific record in the drill-down table of the form (bottom table) and select to open the record (in its native Raiser's Edge application form no less), e.g. see Robert Hernandez's constituent RE form below.

This is only the beginning. We have tons of ideas in our plans to continue improving this product. Go request a download and get a trial version. Give it a whirl and provide us some feedback. If you have any questions go to our contact page or send us an email.
Check back later and we will hopefully have more posts on the Raiser's Edge Data Profiler!